后缀自动机(SAM)
是啥?
顾名思义,后缀自动机是对于一个字符串 S,能够接收 S 的所有后缀的自动机。
我们自然的可以想到,可以像建 Trie 一样,暴力插入 S 的所有后缀,这样每个状态都代表 S 的一个子串。但是这样先不管时间复杂度,就连状态都是 O(∣S∣2) 的,所以我们考虑优化。
咋优化?
我们考虑将上述过程形成的“等价”状态压缩起来。
考虑对于一个 S 的子串 s,定义一个集合 endpos(s) 为 s 在 S 中出现的结尾位置集合。比如对于 S="abab",它的子串 endpos 如下:
| s= |
"a" |
"b" |
"ab" |
"ba" |
"aba" |
"bab" |
"abab" |
| endpos(s)= |
{1,3} |
{2,4} |
{2,4} |
{3} |
{3} |
{4} |
{4} |
我们考虑对 S="abab" 暴力插入后缀,得到的 Trie 长这样:
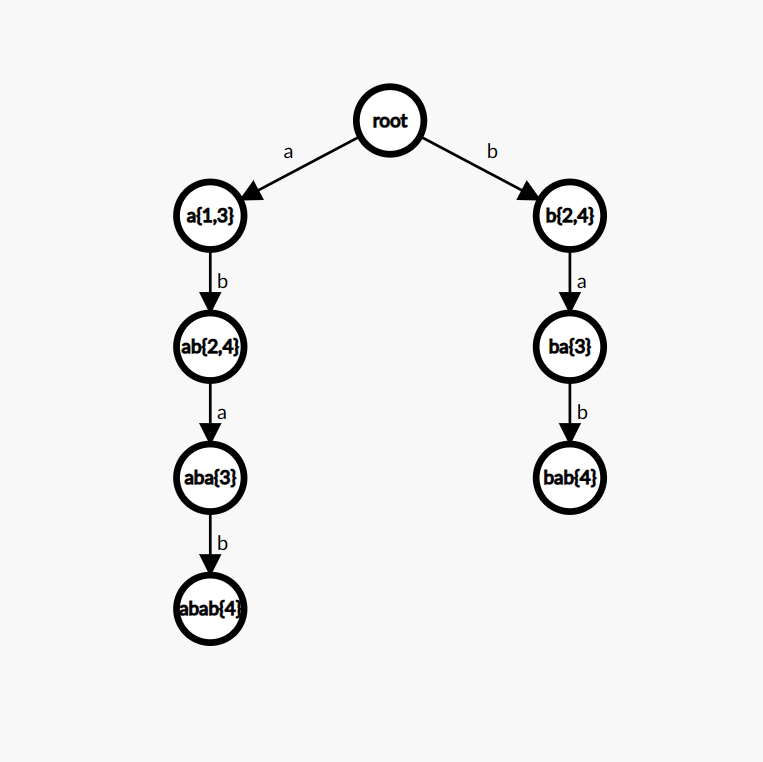
是否可以发现什么?对于 endpos 相同的 s,它在 Trie 上转移到的节点 endpos 构成的集合是相同的。比如说,s="ab" 与 s="b" 都满足 endpos(s)={2,4},而这两个节点所转移到的 endpos(t) 都等于 {3}。
证明也是显然的,在某个 s 后面添加一个字符 ch 所得到的新 endpos 显然等于 {p∣p∈endpos(s),Sp+1=c},而这只与 endpos(s) 有关。
所以,我们可以将 endpos(s) 相同的 s 压缩为一个状态,建出来 SAM 之后长这样:
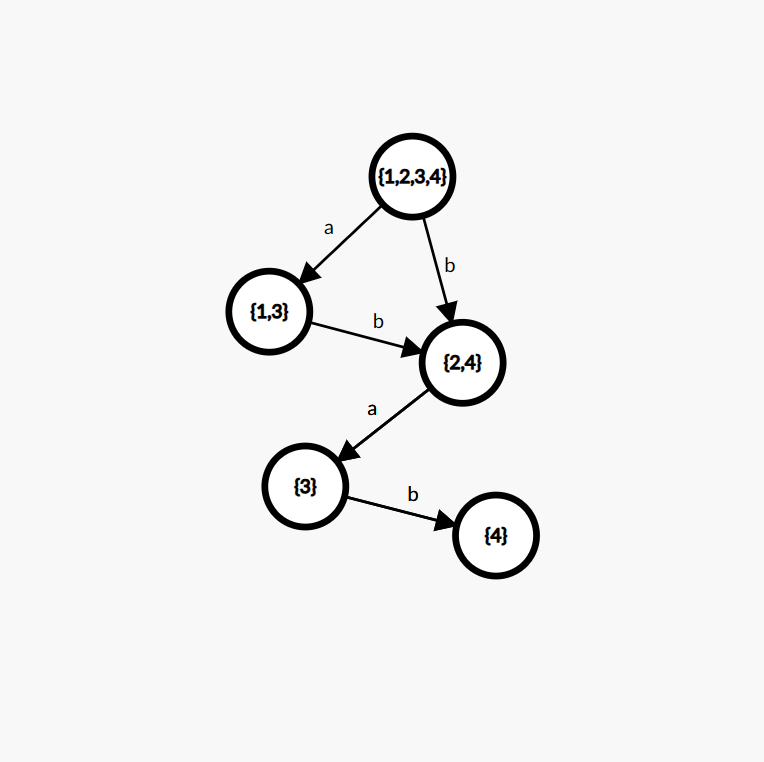
一些性质?
好了,问题来了,既然我们把 endpos 相等的 s 压缩到一个状态里,那我们应该如何高效地记录这个压缩后的状态所对应的所有子串呢?假设状态 stu={s∣endpos(s)=u},则有以下结论:
- stu 中不存在两个不同且长度相等的字符串。
证明显然,如果存在,这两个字符串的 endpos 一定不同。
- 假设两个字符串 sa,sb∈stu 且 sa=sb,∣sa∣<∣sb∣,那么 sa 是 sb 的一个后缀。
证明显然,对于一个 p∈endpos(sa),sa=S[p−∣sa∣+1:p],sb=S[p−∣sb∣+1:p],所以结论成立。
- stu 中字符串的长度一定是一个连续的区间 [l,r]。
我们可以证明:假设对于一个 p∈endpos(sa),stu 中有两个字符串 x,y(∣x∣<∣y∣),则对于所有的 ∣x∣<k<∣y∣,stu 中都会出现长度为 k 的字符串 z。
根据结论 2,x 是 z 的后缀,而 z 是 y 的后缀,所以 endpos(x)⊆endpos(z)⊆endpos(y)。又因为 endpos(x)=endpos(y),所以 endpos(x)=endpos(z)=endpos(y),证明完成。
好了,对于上面的疑问,我们可以得到一个答案:只需要对每个状态,记录长度区间的两个端点 [shortu,lenu],即可得到 stu={S[p−o+1:p]∣shortu≤o≤lenu}。
后缀指针?
考虑引入后缀指针 fru,其中 fru=endpos(S[p−shortu:p])。特别的,u={1,2,…,n} 不存在 fru。由 endpos 的定义可知 fru 一定存在,且 u⊂fru,lenfru=shortu−1,所以记录了 fru 就不需要记录 shortu 了。
可以发现,从一个节点 u 一直跳 fru,会遍历到 S[p−lenu+1:p] 的所有后缀,直到跳到空节点 {1,2,…,n}。所以,如果连接所有的 u→fru 的边,会构成一棵以 {1,2,…,n} 为根的内向树,我们称之为后缀树。
怎么建?
以下我们令 u 后面增加一个字符 c 所到达的状态为 tou,c。
我们考虑初始令 S 为空,然后每次在 S 后面加入一个字符,并动态维护 S 的 SAM。显然,初始的 SAM 只有一个根节点 rt。假如我们要在后面加入一个字符 ch,然后执行以下一系列操作:
-
设当前 S(加入 ch 前)所代表的状态为 la(即 {∣S∣}),新增一个状态 nw={∣S+ch∣},令 lennw=lenla+1;
解释:增加新状态并更新长度,正确性显然。
-
令指针 p 初始时等于 la:
- 如果 top,ch 为空,则令 top,ch=nw,p=frp 并继续更新。
- 如果 p 跳到根 top,ch 仍为空,令 top,ch=nw,frnw=p,退出循环并终止操作。
- 否则令 q=top,ch 并跳出。
解释:top,ch 为空说明在原本的 S 中不存在 p∈endpos(s),Sp+1=c,所以加入 ch 后就存在一个 ∣S∣ 是这样的 p 了,应该令 top,ch=nw={∣S+ch∣}。至于 2. 中 frnw=p 的操作则是因为任意一个 S+ch 的后缀 endpos 都等于 {∣S+ch∣}。而且 la 到根的这条链上必定只有最开始一段 top,ch 为空,因为往回跳的过程中 endpos 是变大的。
-
若 lenq=lenp+1,我们直接向 q 所代表的状态中并入 ∣S+ch∣,并令 frnw=q,终止操作。
解释:lenq=lenp+1 意味着 p 后面加入 ch 得到的新集合 len 没有因为 endpos 限制变松而变大,所以我们相当于舍弃了原先的状态并新增了一个状态 q′=q∪∣S+ch∣,因为只是加入了一个最右边的位置,所以 toq′,∗=toq,∗。frnw=q 的操作也是显然的。
-
否则我们新增一个状态 q′,令 toq′,∗=toq,∗,frq′=frq,lenq′=lenp+1,frnw=frq=q′。
解释:类似于前一种情况,只不过 lenq 因为限制变松而变大了。我们保留原先的 q,类似地新增 q′=q∪∣S+ch∣,并拷贝 to,fr,lenq′=lenp+1 以收紧限制。frq=q′ 的操作也是显然的。
-
令指针 tp 初始时等于 p:
- 如果 top,ch=q,令 top,ch=q′。
- 如果 p 不为根,令 p=frp,否则跳出循环。
解释:为每个原本指向 q 的节点都更新限制,让其指向限制更新的 q′。p 到根的这条链上必定只有最开始一段 totp,ch=q,因为往回跳的过程中 totp,ch 是变大的。
复杂度?
因为每次插入只会新增最多两个点,所以状态数是 O(n) 的。
转移数也是 O(n) 的,时间复杂度视实现为 O(nlog∣Σ∣) 或 O(n∣Σ∣),证明见 OI Wiki。
空间复杂度视实现为 O(n) 或 O(n∣Σ∣)。
代码?
实现时并没有必要记录一个状态具体的 endpos,这样信息就太多了。
namespace SAM{int n, cn, la;
struct node{int fr, mxl, to[S];}tr[N];
void init(int _n){n = _n, cn = la = 0;
tr[0].fr = -1, memset(tr[0].to, -1, sizeof(tr[0].to));
}
void addch(int x){int nw = ++ cn, p = la, q, qq;
tr[nw].mxl = tr[la].mxl + 1,
memset(tr[nw].to, -1, sizeof(tr[nw].to));
for (;p != -1;p = tr[p].fr)
if (tr[p].to[x] != -1){q = tr[p].to[x];break;}
else tr[p].to[x] = nw;if (p == -1){tr[nw].fr = 0;goto End;}
if (tr[p].mxl + 1 == tr[q].mxl){tr[nw].fr = q;goto End;}
tr[tr[nw].fr = qq = ++ cn] = tr[q], tr[qq].mxl = tr[p].mxl + 1;
while (p != -1 && tr[p].to[x] == q) tr[p].to[x] = qq, p = tr[p].fr;
tr[q].fr = qq;End:la = nw;
}
}
这里顺便给一个 SAM 可视化的链接,输入字符串就可以画出对应的 SAM,非常 nb。
例题
考虑建出后缀树,然后对于一个状态,该状态中的字符串出现次数即为 endpos 大小,最长长度为 len。所以我们只需要对于每个状态求出 szu=∣endpos∣ 即可。
具体的,构建 SAM 时令每一个前缀 pr,szpr=1,但是复制状态时无需复制 sz,最终在后缀树上求一次子树和。为什么不用复制 sz?因为 frq=q′,可以将 sz 更新到 q′ 上。
考虑建出 SAM,然后在上面 dp 求一遍 DAG 路径数即可。
还有另外一个做法,就是建出后缀树,然后状态 u 中的字符串种类数就是 lenu−lenfau。对所有的状态求和即可。